项目背景
长期以来,由于监管导向和业务连续性要求,国内金融行业信息系统普遍强调业务系统的高可用性和高稳定性。某金融公司现有设备为两台华为的S5500V5存储,计算资源为十多台X86服务器,其中两台存储分别处于总行数据中心和同城灾备数据中心,系统架构为Oracle RAC+ VMware 虚拟化,目前所有的业务系统只考虑到现有数据中心的节点故障,不能预防整个数据中心的故障,亟需构建新的容灾体系,满足业务连续性的监管要求。
项目建设目标
通过新购服务器和存储设备,采用新的架构进行容灾的设计,有望达成本次项目目标:在主数据中心不可访问后,灾备数据中心可以对外提供服务,同时可以避免单个存储或者网络不稳定导致的数据丢失或者网络不可达问题。
关键问题
同城双活的建设,是为业务连续性提供服务,在发生故障后,尽最大可能的保障数据能够被恢复,业务能够快速的恢复服务。因此在整个方案中需要尽可能多的假设各种故障场景,考虑各场景的应对方案,才能尽量减少在系统运行中发生的预期外的异常,保障系统的正常运行。
在整个方案中,重点需要关注以下的几个方面。
1、Oracle 仲裁
⽹络⼼跳
⽹络⼼跳主要是确保集群节点间的连通性,以便节点之间能够了解彼此的状态。ocssd.bin 进程每秒向其他节点发送⽹络⼼跳,通过⼼跳情况确认节点的连通性,以及当⽹络⼼跳出现问题时做出处理。若某个节点的网络心跳在 misscount 指定的秒数中都没有被收到的话,该节点被认为已经“死亡”。在出现集群分裂的情况下,基于简单多数原则,拥有节点数量多的子集群存活。若是节点数一致则 RAC 会选择保留拥有最低节点号节点的子集群。
磁盘⼼跳
如果由于⽹络⼼跳异常,导致集群出现脑裂的发⽣,磁盘⼼跳则帮助解决该问题。Oracle 集群的每㇐个节点每秒都会向集群中所有的表决盘注册本地节点的磁盘⼼跳信息, 也就是说,所有的Voting File 的信息是相同的。同时会将⾃⼰能够联系的到的集群中的其他节点的信息,或者说本地节点认为集群中的成员列表信息填⼊到表决盘中。㇐旦发⽣脑裂, CSS 的重新配置线程就会通过表决盘的信息了解集群节点间的连通性,从⽽决定集群会分裂成⼏个⼦集群,以及每个⼦集群所包含的节点情况和每个节点的状态。如果发现某个节点在指定的时间内没有写入磁盘心跳,这个节点就被判决为死亡。如果一个节点处于未知状态,其他节点也会通过更新它的 voting disk 上的 kill block 状态的方式把它驱逐出集群。
总的来说,网络心跳每秒都会发起,如果一个节点超出了参数 css_miscount time 设定的时间没有响应,就会被踢出集群。类似的,集群里的每个节点每秒读写voting disk 特定区域,出现超时响应的节点也会被踢出集群。发生集群分裂的情况下,根据表决盘中的信息,判断集群分裂情况,按照简单多数原则和最低节点号的原则保留活动节点。
2、同城双活中心间链路抖动问题
若出现链路延迟较大或者频繁出现连接中断,都可能会对系统的运行造成重大影响。双活中心的链路质量需要注意的事项:
1. 在进行链路设计时,需要充分考虑链路的冗余。从波分设备、交换机、存储和主机接入都需要进行详细的规划设计,保证任一环节不存在单点故障。而对于不受控的运营商线路,需要同时租用两家以上的运营商裸纤,有条件的话,对运营商的裸纤的路线和进入数据中心的弱电井等进行详细了解,尽量避免存在物理空间上的交叉。
2. 对链路质量进行检测,包括光衰、延迟、抖动等。最好在双活建设之前进行链路质量的测试和检测,及时发现问题并与运营商进行沟通处理。
3. 做好链路抖动或延迟大的处理预案。当出现链路抖动或者延迟大的情况下,需要按照设计好的方案断开线路,已保障其中一个站点能够正常的提供服务。结合自动化运维监控,在发生该问题时,能够自动切断链路,一边在一个中心正常提供业务。
3、性能下降问题
由于在存储双活方案中采用双写保证数据的一致性,故对于数据写操作的延迟会增加, 特别是采用 VPLEX 类似的存储网关方案时较为明显。在系统并发写操作大时,写 IO 的延迟会明显增加,系统的 TPS 将会受到影响。故需要在投产之前做好性能压力测试,已满足投产后的正常运行。
另外,在VPLEX Metro 双站点间链路中断的情况下,IO 将会 hang 住 5 秒,在这 5s 内产生的会话连接将会消耗主机 CPU、内存资源,若是每秒 1000 个数据库并发的情况下, 将会产生 5000 个的会话连接,需要根据实际情况估算数据库主机的相关资源,以免在 IO hang 的期间将主机资源耗尽从而导致宕机。
4、运行维护问题
双活容灾解决方案将灾难切换变的较为简单,但在实际的维护方面并不简单,除了要求用户提升自己的维护能力,还需双活容灾解决方案供应商的售后服务能力。
用户自身人员的维护能力必须加强,才具备能力维护跨站点的双活系统。
用户运维人员必须从维护设备的能力转变为具备维护双活系统架构的能力,需要深入了解双活架构中的各个环节,才能保障系统的正常运行。
双活容灾解决方案供应商的售后服务能力
供应商的服务能力也直接影响双活容灾系统部署后的效果,在许多的案例中,经常看到供应商提供了400 电话,但却不能及时安排技术人员现场服务。整个服务过程重复的在收集日志进行诊断,在问题出现的时候,难以尽快解决问题,这样的方式如何保障双活容灾系统的稳定?所以后期的有效沟通和及时的技术支持是需要关注的问题。
需要结合运维监控和运维自动化完成双活数据中心的运行管理。
假设双活中心的中间链路出现抖动,导致IO 延迟大,若没有完善的监控系统,我们发现的时候可能主机已经由于不能正常进行 IO 读写而导致了宕机。即使有监控系统,并且已经发送告警给系统管理员,但是系统管理员需要登录相关设备进行问题查看,并按照应急的方案进行处理,这个过程是需要时间的。若是在业务高峰期发生该情况,将对大量的业务交易造成影响,甚至由于宕机而导致一段时间的业务交易不能正常进行。故需要结合运维监控和运维自动化系统,由系统快速的做出响应。
总体架构设计
1、双活数据中心网络设计(大二层网络的vxlan)
随着网络技术的发展,云计算凭借其在系统利用率高、人力/管理成本低、灵活性/可扩展性强等方面表现出的优势,已经成为目前企业IT建设的新趋势。而服务器虚拟化作为云计算的核心技术之一,得到了越来越多的应用。
服务器虚拟化技术的广泛部署,极大地增加了数据中心的计算密度;同时,为了实现业务的灵活变更,虚拟机VM需要能够在网络中不受限迁移,这给传统的“二层+三层”数据中心网络带来了新的挑战。
VXLAN技术的优势
针对虚拟机规模受设备表项规格限制
VXLAN将管理员规划的同一区域内的VM发出的原始报文封装成新的UDP报文,并使用物理网络的IP和MAC地址作为外层头,这样报文对网络中的其他设备只表现为封装后的参数。因此,极大降低了大二层网络对MAC地址规格的需求。
针对网络隔离能力限制
VXLAN引入了类似VLAN ID的用户标识,称为VXLAN网络标识VNI(VXLAN Network Identifier),由24比特组成,支持多达16M的VXLAN段,有效得解决了云计算中海量租户隔离的问题。
针对虚拟机迁移范围受限
VXLAN将VM发出的原始报文进行封装后通过VXLAN隧道进行传输,隧道两端的VM不需感知传输网络的物理架构。这样,对于具有同一网段IP地址的VM而言,即使其物理位置不在同一个二层网络中,但从逻辑上看,相当于处于同一个二层域。即VXLAN技术在三层网络之上,构建出了一个虚拟的大二层网络,只要虚拟机路由可达,就可以将其规划到同一个大二层网络中。这就解决了虚拟机迁移范围受限问题。
VXLAN目的
在同城灾备系统中,采用存储双活或者是同步复制的方式,虚机机在还原后,ip地址也会被保留,如果两个集群网段不通,势必会造成业务无法访问,当采用大二层技术后,网络对于VM虚拟机相当于是透明的,可以不受异地网络网关不同的限制。
2、应用级容灾解决方案(不依赖于存储)
内容简介
应用级容灾解决方案,从应用层面实现业务的连续性,不依赖于底层硬件,对网络时延要求比较宽容。Dell EMC RecoverPoint 复制技术基于VM虚拟化,提供了在任意受支持的存储阵列、任意地点,将任意应用程序恢复到任意时间点所需的连续数据保护。通过即时访问数据,实现恢复点目标 (RPO) 和恢复时间目标 (RTO)。您可以使用 RecoverPoint 来支持灾难恢复、操作恢复和测试。
方案设计
目前数据中心主机业务分为Oracle RAC数据库和 VM 集群。
Oracle本地通过RAC高可用技术实现单点故障,远程通过Oracle DG实现实时复制功能。
VMware通过EMC RecoverPoint for VM,实现虚拟机的复制功能,同时EMC RecoverPoint for VM支持多副本保存,可以恢复到任意时间点。
逻辑图
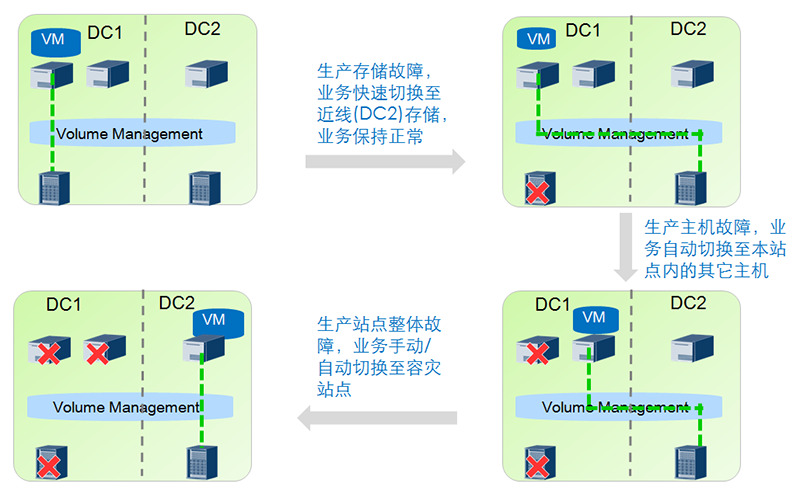
同城应用级容灾应用效果